为 AI 视频工作流开发的两个 ComfyUI 插件
最近在做一个AI视频项目时,遇到了一个很实际的问题:如何用AI生成具有一致性的多角度镜头? 无论是电影预告片、漫剧分镜,还是产品展示视频,都需要在不同角度展示同一个场景或角…
最近在做一个AI视频项目时,遇到了一个很实际的问题:如何用AI生成具有一致性的多角度镜头? 无论是电影预告片、漫剧分镜,还是产品展示视频,都需要在不同角度展示同一个场景或角…
三个月前,我写了《2026 年 AI 图像生成趋势观察:工具如何重塑创作者生态》。那篇文章意外获得了很多点击。 “这些工具到底哪个值得学?我只想提高效率,不想把…
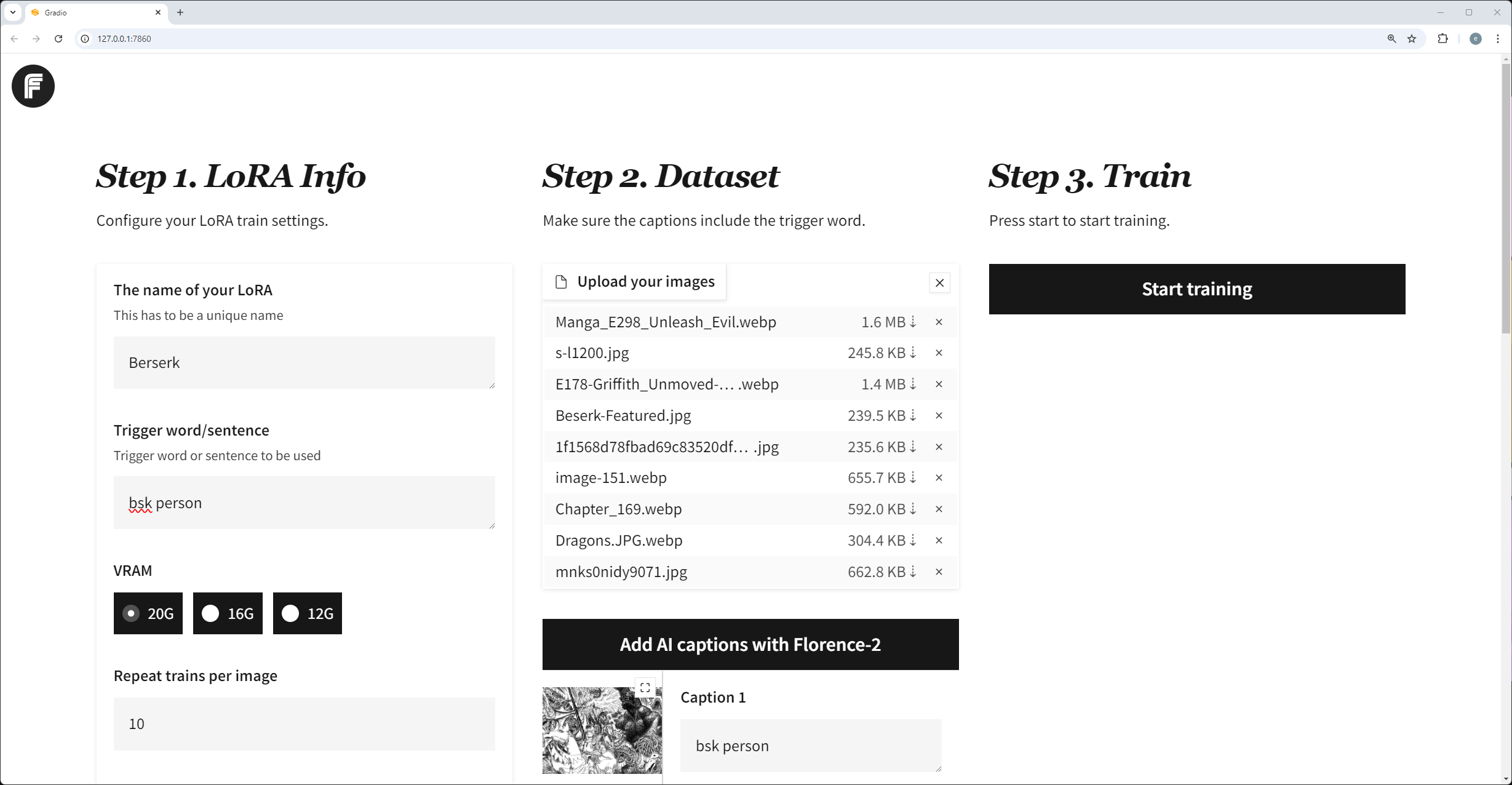
这个模型基于flux-dev版模型训练的lora,具备很好的泛化能力。二次元风格,这个模型可以结合线稿、参考姿势结合union-controlnet-v2模型一起使用,能够…
黑森林团队出的flux模型因其强大的参数,惊艳的细节效果广受欢迎,现在已经在各类AIGC平台占有很大的曝光量,甚至现在libulibu首页也是主推f1.0的lora模型,因…
上一期文章分享了扁平插画女孩的LoRa-XL模型,训练的repeat扫描次数在10-20之间,这次我将他们的repeat提高到100-150,在同样的提示词下生成的效果如图…
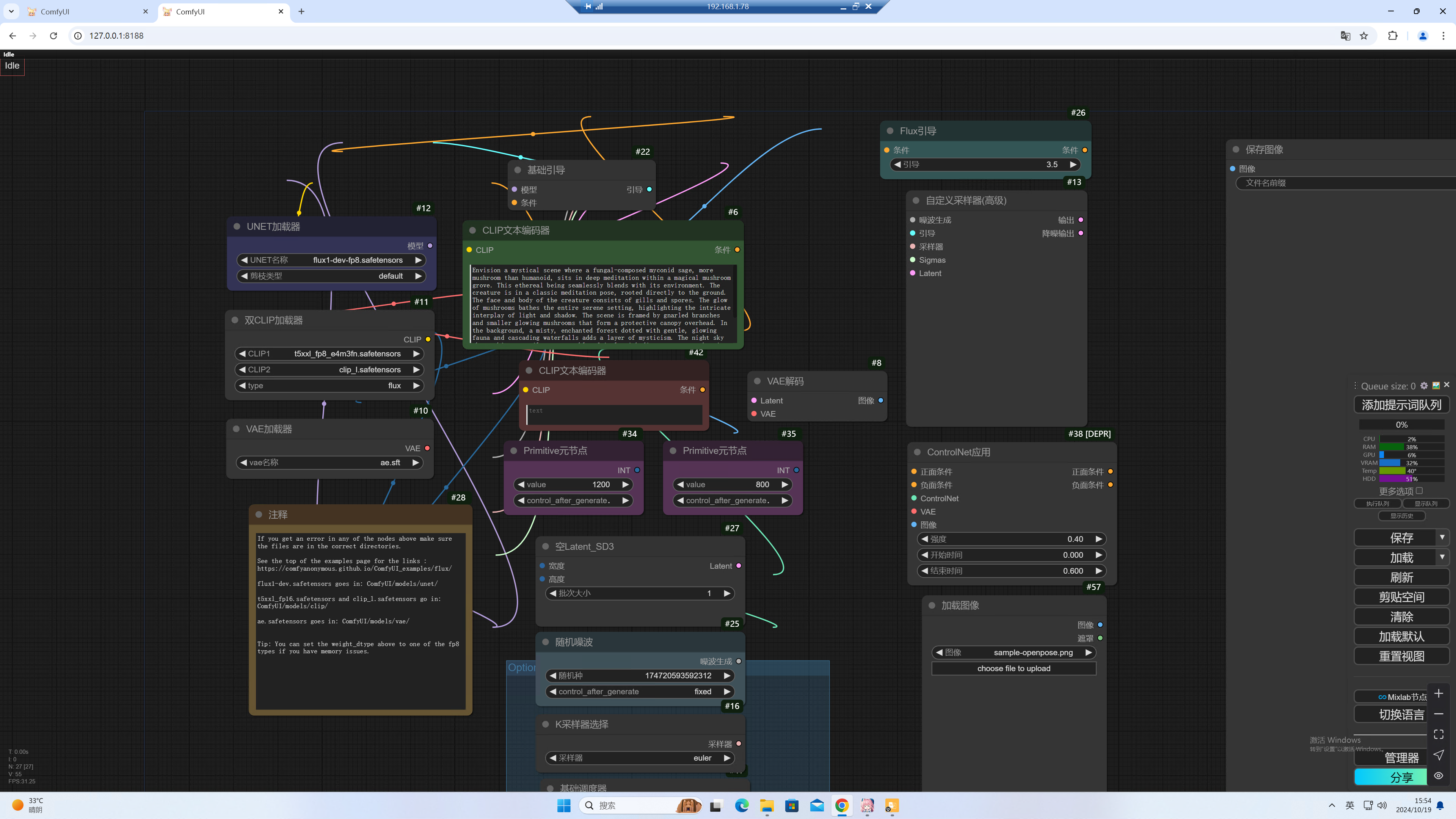
这个问题没有发生在我身上,是同事在使用comfyui过程中遇到的问题。出现这个问题的场景是在启动工作流之后,loading出界面会出现已经连线完好的工作流程连线会断开的情况…
看了这个作者的演示,效果确实不错,但是我细查了下发现是培训机构的。所以想要获取他的流程必须要三连加微信才能获取到,而且一时半会还没发给我。本着提升自己对comfyui的熟悉…
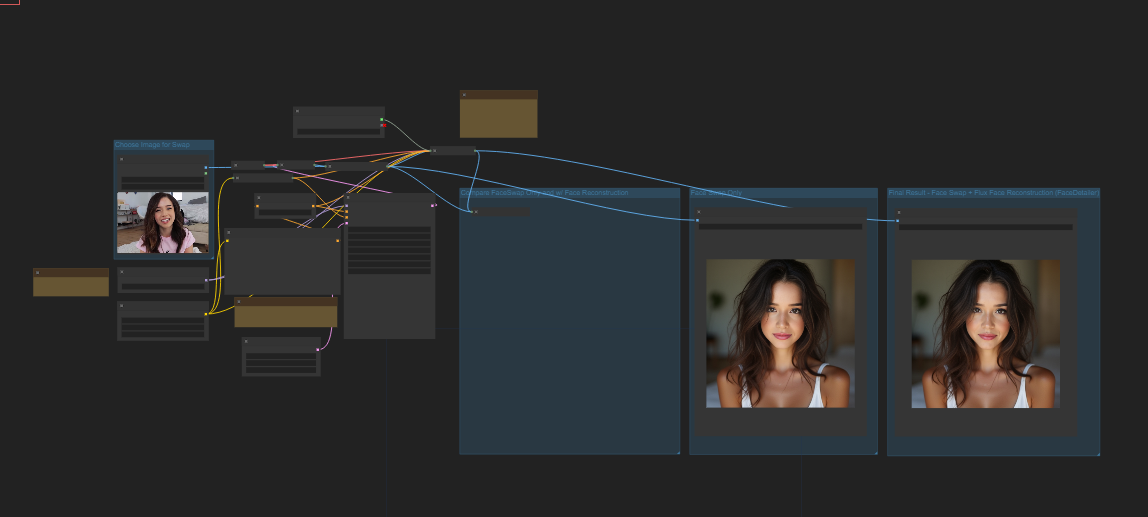
这个问题搞到最后把我自己逗乐了,我暂且还原下我在配置这个工作流环境遇到的问题。 这个工作流来自civitai 老外分享的一个换脸工作流,我将其导入本地comfyui之后照常…
我为什么分享这个工作流失是因为我有过电商服装、护肤品视觉设计的工作经历,其次加上flux模型的加持,改善手指的正确刻画搭配flux-lora真实模型这个工作流在ComfyU…
我预计 Flux 模型将会是在视觉模型中长期霸榜,生成风格的多样性、对人物肢体的控制,都是其他模型无法比拟的。接下来我将展示2个流程来具体看看它的生成质量。 案例一 迪斯尼…