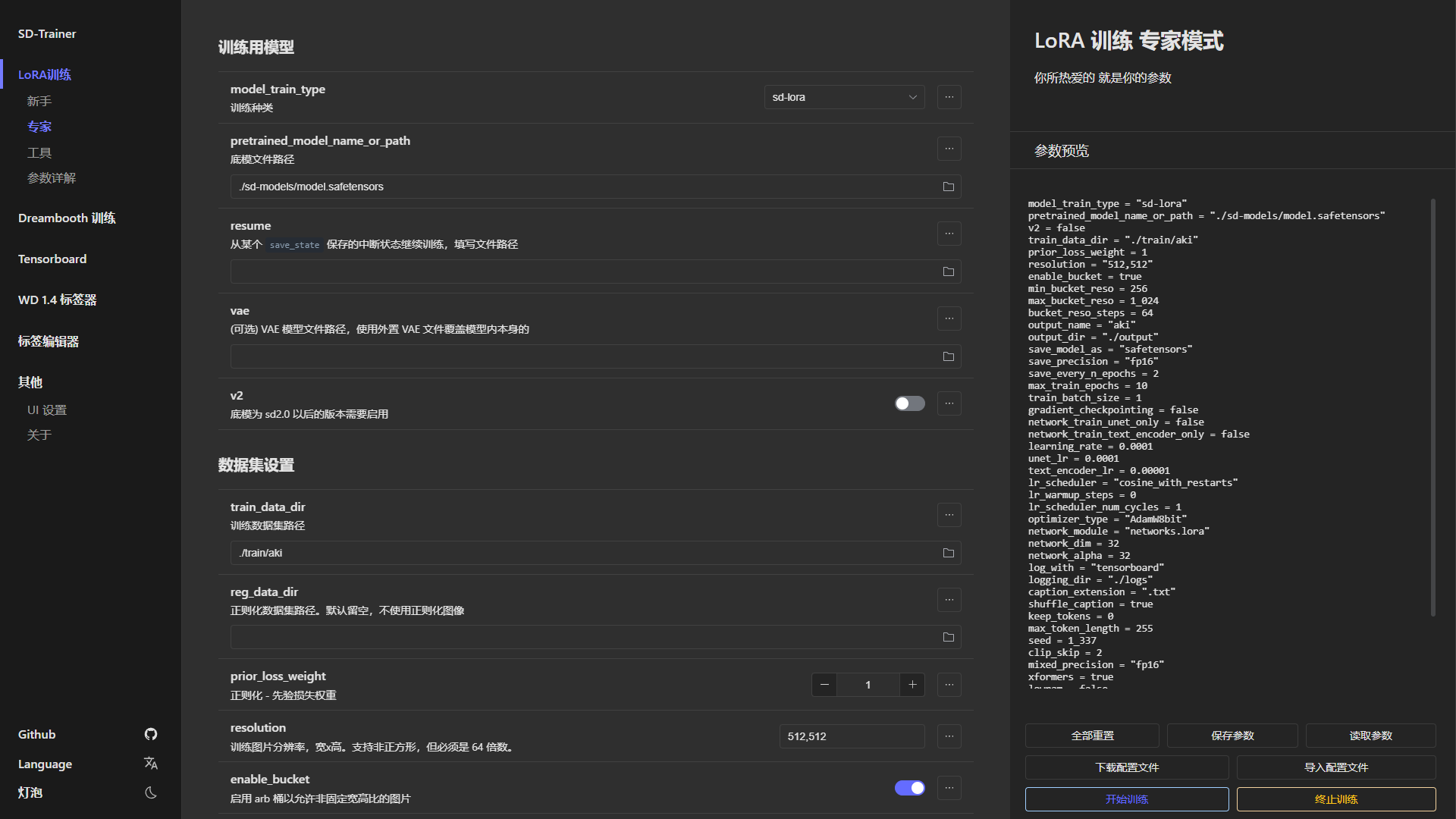
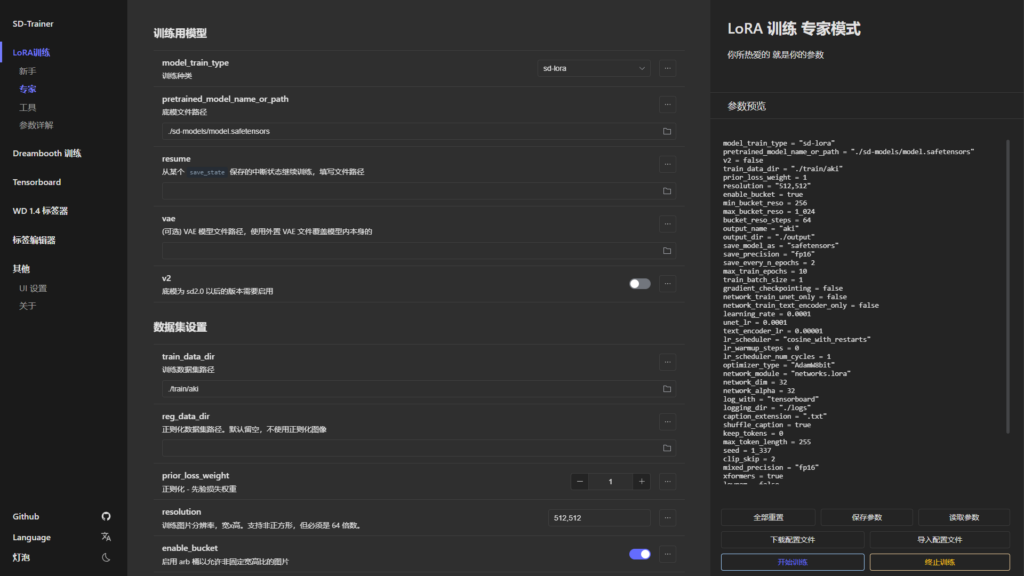
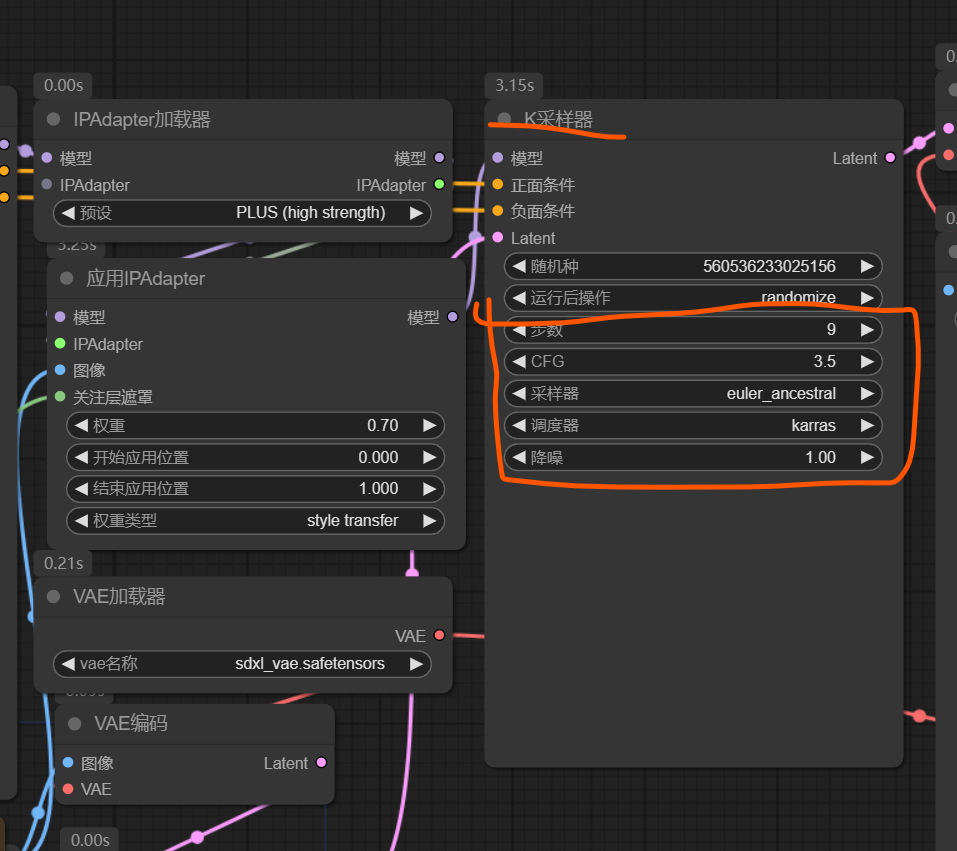
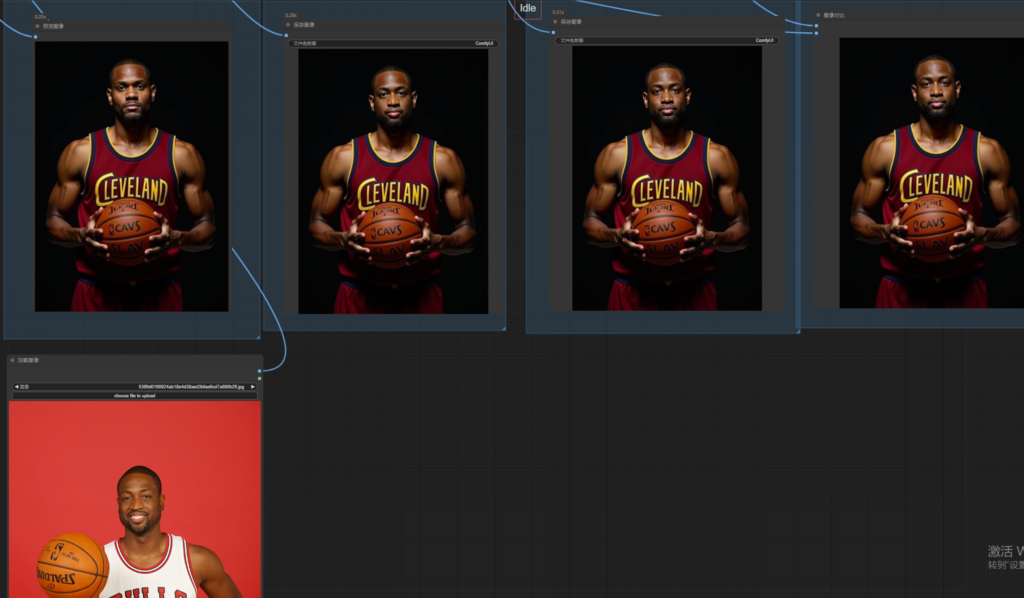
masterpiece:(1.2),chahua_nvhai,,British girl,Exquisite facial details,long hair,1girl,illustration style,brown hair,wear blue dress,illustration, 5 fingers,8K,hud,Grand Budapest Hotel background,happy
masterpiece:(1.2),chahua_nvhai,fullbody,British girl,Exquisite facial details,long hair,1girl,illustration style,brown hair,wear blue dress,illustration, 5 fingers,8K,hud,Grand Budapest Hotel background,happy